
Software Engineer based in Raleigh, NC. Interested in distributed systems.


How to Write a Lexer in Go
June 01, 2020
A lexer is the first phase in all modern compilers, but how do you write one? Let’s build one from scratch in Go!

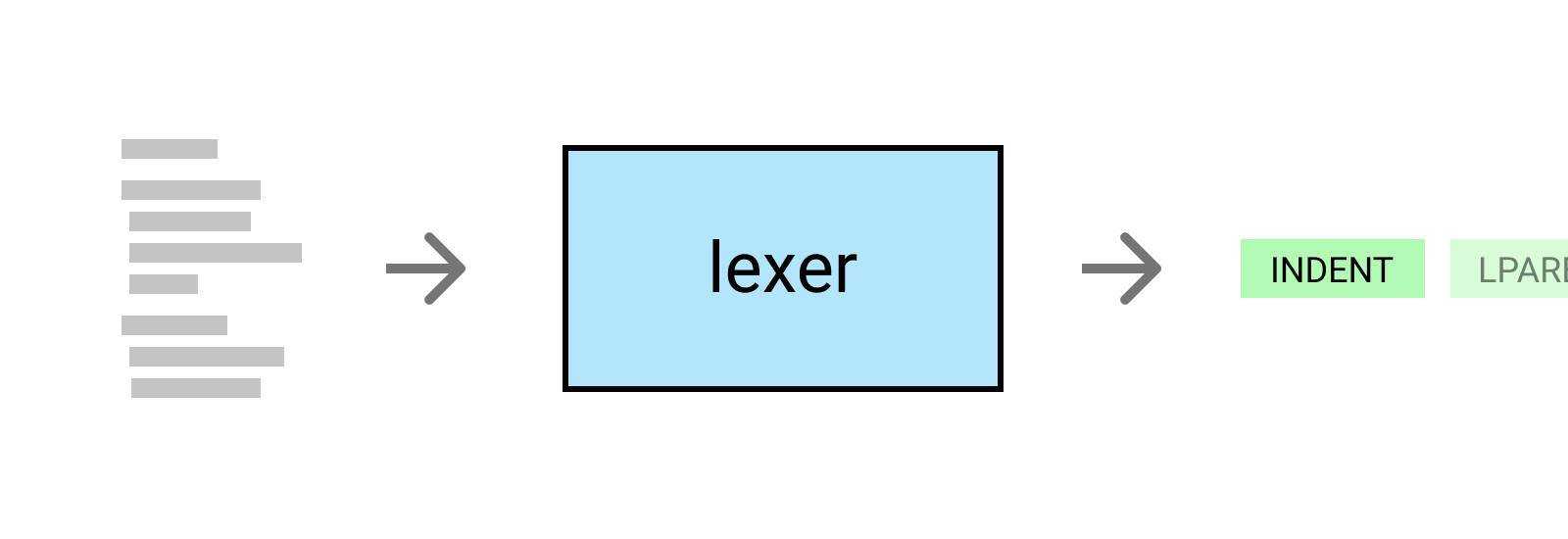
What is a lexer?
A lexer, which is also sometimes referred to as a scanner, reads a source program and converts the input into what is known as a token stream. This is a very important step in compilation since these tokens are used by the parser to create an AST (Abstract Syntax Tree). If you are unfamiliar with parsers and ASTs, don’t worry! This post is going to focus only on building a lexer.
A lexer in action
Before we write our own lexer, let’s take a look at Go’s lexer to get a better idea of what is meant by a “token”. You can use Go’s scanner package to take a look at exactly what tokens are emitted by Go’s lexer. There is an example of how to do that in the documentation. Here is the program that we will put through the scanner:
main.go
package main
import "fmt"
func main() {
fmt.Println("Hello world!")
}And here are the tokens that are emitted:
output
1:1 package "package"
1:9 IDENT "main"
1:13 ; "\n"
3:1 import "import"
3:8 STRING "\"fmt\""
3:13 ; "\n"
5:1 func "func"
5:6 IDENT "main"
5:10 ( ""
5:11 ) ""
5:13 { ""
6:2 IDENT "fmt"
6:5 . ""
6:6 IDENT "Println"
6:13 ( ""
6:14 STRING "\"Hello world!\""
6:28 ) ""
6:29 ; "\n"
7:1 } ""
7:2 ; "\n"The first column contains the token's position, the second is the token’s type, and the final column is the literal value of that token. There are a few important things to take note of here. First off, the lexer does not emit any tabs or spaces. This is because Go’s syntax does not rely on these things. Another thing to notice is the IDENT tokens. Basically, anything that is not a keyword in Go will be marked as an identifier and the accompanying string will be noted as the literal value.
If you are wondering why these tokens are useful, it’s because they represent the source program in a way that the parser can understand!
Our language
Now that we have taken a look at a lexer in practice, let’s build our own from scratch! We first need to define a grammar for our programming language. To keep it simple, let’s only include a few different things:
program → expr*
expr → assignment | infixExpr | int
assignment → id = expr ;
infixExp → expr infixOp expr ;
infixOp → + | - | * | /
Anything that is bolded is called a terminal, meaning that it cannot be expanded any further. The terminals are very important when building a lexer, and we will see that later. The grammar can be read like this:
A program is a list of zero or more expressions. An expression is either an assignment, an infix expression, or an integer. And so on…
The grammar becomes much more important when building a parser, but it’s important to define a grammar now so that we know what tokens our lexer should emit!
Our tokens
The grammar above allows us to define the tokens that our lexer should emit when scanning. The tokens are simply just the terminals! We will also include an EOF and ILLEGAL token to allow us to signal the end of the program and characters that are not legal in our language, respectively.
lexer.go
type Token int
const (
EOF = iota
ILLEGAL
IDENT
INT
SEMI // ;
// Infix ops
ADD // +
SUB // -
MUL // *
DIV // /
ASSIGN // =
)
var tokens = []string{
EOF: "EOF",
ILLEGAL: "ILLEGAL",
IDENT: "IDENT",
INT: "INT",
SEMI: ";",
// Infix ops
ADD: "+",
SUB: "-",
MUL: "*",
DIV: "/",
ASSIGN: "=",
}
func (t Token) String() string {
return tokens[t]
}Scanning the input
We’re now ready to scan the source program and emit some tokens! We’ll start by creating a Lexer struct that will hold some state:
lexer.go
type Position struct {
line int
column int
}
type Lexer struct {
pos Position
reader *bufio.Reader
}
func NewLexer(reader io.Reader) *Lexer {
return &Lexer{
pos: Position{line: 1, column: 0},
reader: bufio.NewReader(reader),
}
}The caller will be expected to create a reader with the appropriate source file and pass it as an argument when creating a Lexer.
Next, let’s add a Lex function that returns a single token at a time. The caller will then be able to continuously call Lex until an EOF token is returned. First, let’s handle the case where we are at the end of the input file.
lexer.go
// Lex scans the input for the next token. It returns the position of the token,
// the token's type, and the literal value.
func (l *Lexer) Lex() (Position, Token, string) {
// keep looping until we return a token
for {
r, _, err := l.reader.ReadRune()
if err != nil {
if err == io.EOF {
return l.pos, EOF, ""
}
// at this point there isn't much we can do, and the compiler
// should just return the raw error to the user
panic(err)
}
}
}Then let’s add some logic to take care of some of the more basic terminals in our grammar. We can use a switch statement to check if we have come across one of our terminals:
lexer.go
func (l *Lexer) Lex() (Position, Token, string) {
// keep looping until we return a token
for {
…
// update the column to the position of the newly read in rune
l.pos.column++
switch r {
case '\n':
l.resetPosition()
case ';':
return l.pos, SEMI, ";"
case '+':
return l.pos, ADD, "+"
case '-':
return l.pos, SUB, "-"
case '*':
return l.pos, MUL, "*"
case '/':
return l.pos, DIV, "/"
case '=':
return l.pos, ASSIGN, "="
default:
if unicode.IsSpace(r) {
continue // nothing to do here, just move on
}
}
}
}
func (l *Lexer) resetPosition() {
l.pos.line++
l.pos.column = 0
}This allows us to lex everything except identifiers and integers, which is pretty neat! Let’s handle integers next. We need to detect if we have just seen a digit; and if we have, scan the rest of the digits that follow to tokenize the integer.
lexer.go
func (l *Lexer) Lex() (Position, Token, string) {
// keep looping until we return a token
for {
…
switch r {
…
default:
if unicode.IsSpace(r) {
continue // nothing to do here, just move on
} else if unicode.IsDigit(r) {
// backup and let lexInt rescan the beginning of the int
startPos := l.pos
l.backup()
lit := l.lexInt()
return startPos, INT, lit
}
}
}
}
func (l *Lexer) backup() {
if err := l.reader.UnreadRune(); err != nil {
panic(err)
}
l.pos.column--
}
// lexInt scans the input until the end of an integer and then returns the
// literal.
func (l *Lexer) lexInt() string {
var lit string
for {
r, _, err := l.reader.ReadRune()
if err != nil {
if err == io.EOF {
// at the end of the int
return lit
}
}
l.pos.column++
if unicode.IsDigit(r) {
lit = lit + string(r)
} else {
// scanned something not in the integer
l.backup()
return lit
}
}
}As you can see, lexInt just scans all the consecutive digits and then returns the literal. Handling identifiers can be accomplished in a similar fashion, however, we should define what characters are valid in an identifier. For our language, let’s only allow uppercase and lowercase letters, everything else should be considered an ILLEGAL token.
lexer.go
// Lex scans the input for the next token. It returns the position of the token,
// the token's type, and the literal value.
func (l *Lexer) Lex() (Position, Token, string) {
// keep looping until we return a token
for {
...
switch r {
...
default:
if unicode.IsSpace(r) {
continue // nothing to do here, just move on
} else if unicode.IsDigit(r) {
// backup and let lexInt rescan the beginning of the int
startPos := l.pos
l.backup()
lit := l.lexInt()
return startPos, INT, lit
} else if unicode.IsLetter(r) {
// backup and let lexIdent rescan the beginning of the ident
startPos := l.pos
l.backup()
lit := l.lexIdent()
return startPos, IDENT, lit
} else {
return l.pos, ILLEGAL, string(r)
}
}
}
}
// lexIdent scans the input until the end of an identifier and then returns the
// literal.
func (l *Lexer) lexIdent() string {
var lit string
for {
r, _, err := l.reader.ReadRune()
if err != nil {
if err == io.EOF {
// at the end of the identifier
return lit
}
}
l.pos.column++
if unicode.IsLetter(r) {
lit = lit + string(r)
} else {
// scanned something not in the identifier
l.backup()
return lit
}
}
}That’s it! It’s important to note that lexing does not catch errors like undefined variables or invalid syntax. Its only concern is lexical correctness (i.e. are the characters used allowed in our language). Here is how you can run the lexer and view the output:
lexer.go
func main() {
file, err := os.Open("input.test")
if err != nil {
panic(err)
}
lexer := NewLexer(file)
for {
pos, tok, lit := lexer.Lex()
if tok == EOF {
break
}
fmt.Printf("%d:%d\t%s\t%s\n", pos.line, pos.column, tok, lit)
}
}If you run our lexer on the following input by running go run lexer.go you will see that the tokens are emitted!
input.test
a = 5;
b = a + 6;
c + 123;
5+12;output
1:1 IDENT a
1:3 = =
1:5 INT 5
1:6 ; ;
2:1 IDENT b
2:3 = =
2:5 IDENT a
2:7 + +
2:9 INT 6
2:10 ; ;
3:1 IDENT c
3:3 + +
3:5 INT 123
3:8 ; ;
4:1 INT 5
4:2 + +
4:3 INT 12
4:5 ; ;I hope that you learned something from this post, and I would love to hear your feedback down in the comments section. All of the source code for this post is available on my GitHub. The repository also includes unit tests that I didn’t cover.