
Software Engineer based in Raleigh, NC. Interested in distributed systems.


An Introduction to Producing and Consuming Kafka Messages in Go
June 13, 2020
Kafka is a popular distributed streaming platform. Let’s take a look at how to produce and consume messages in Go!

What is Kafka?
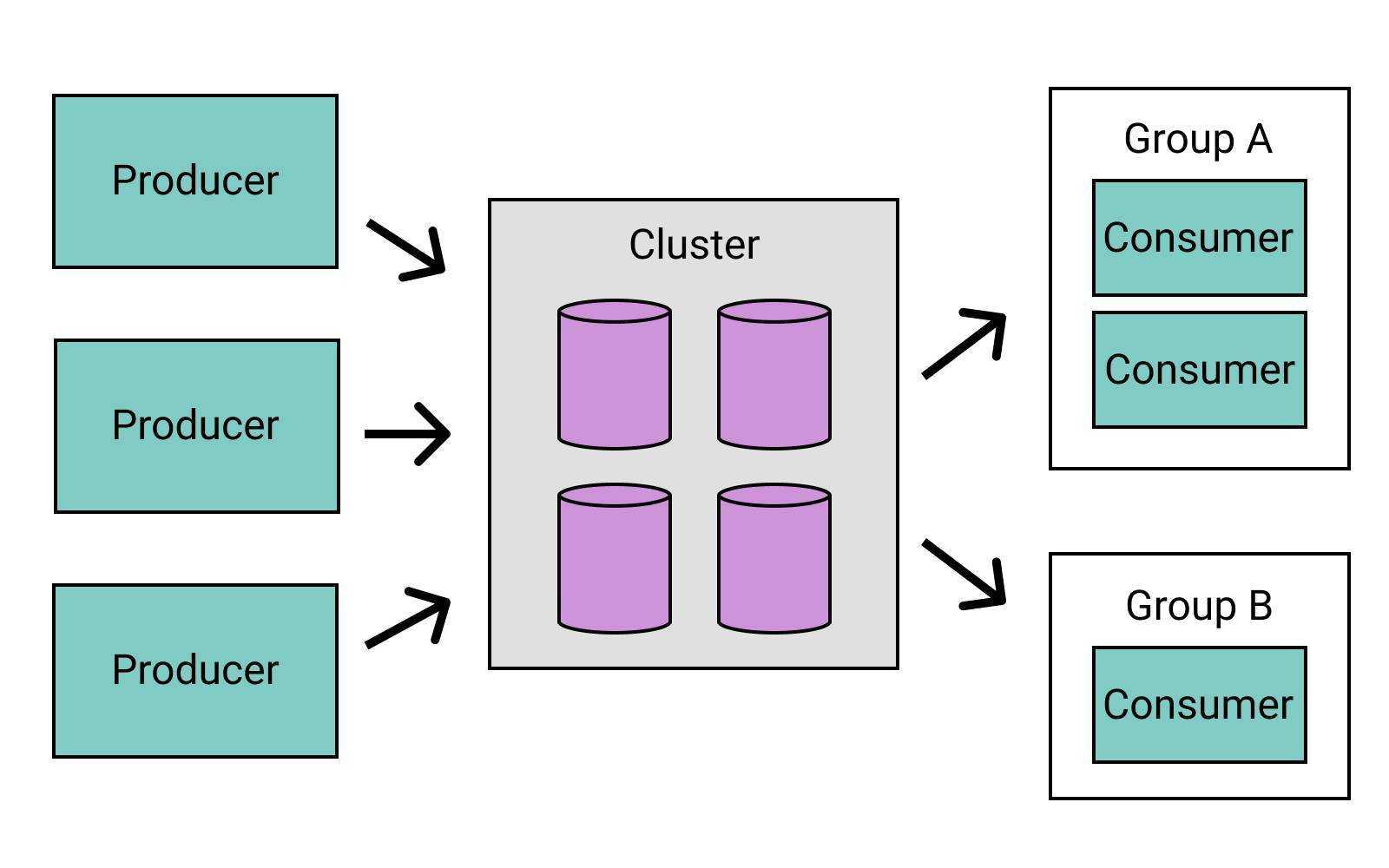
The official documentation describes Kafka as being a “distributed streaming platform”. In many cases it is used as a message queue that microservices produce events to. These events are then consumed and processed by other microservices. This is the use case that this post will focus on, however there are many other ways which Kafka can be used.
There are a few important concepts to understand before starting. A broker in Kafka is another term for a server in the cluster. These brokers manage topics which is a way to group messages together. Producers are processes that write messages to topics, and consumers are processes that read messages from topics. The details about how each of these components are designed are out of scope for this post, but the documentation outlines each of these if you are interested.
Running Kafka locally
All of the examples in this post will be interacting with a Kafka cluster that is running locally on my machine. Getting one set up is fairly straightforward and is explained in detail in the quick start guide. It’s worth noting that my “cluster” will consist of only one node so that we can focus on producing and consuming messages rather than configuring and managing a cluster of servers. Of course, in practice you would want a cluster of multiple machines so that you can take advantage of Kafka’s fault-tolerance.
Producing messages
The package that we will be using is confluent-kafka-go. The examples in this post are adapted from the examples in their repository.
I will be producing to a topic named “test”, but of course you can switch that out for whatever you’d like. If you have not already created a topic, you can do so by running:
command line
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testThis script is inside the Kafka directory. Notice that this topic will not be partitioned or replicated at all, since we only have one machine in our cluster.
The first thing that we need to do is create a producer. We will need to provide it with our bootstrap.servers which is a comma separated list of the brokers in our cluster.
producer.go
func main() {
config := &kafka.ConfigMap{"bootstrap.servers": "localhost:9092"}
producer, err := kafka.NewProducer(config)
if err != nil {
log.Fatalf("Error creating producer: %s\n", err)
}
}Next, we will create a message to be sent to the broker. We will need to include what topic and partition we want to send the message to as well. Since we don’t care about the specific partition we can just use kafka.PartitionAny.
producer.go
func main() {
...
topic := "test"
record := &kafka.Message{
TopicPartition: kafka.TopicPartition{
Topic: &topic,
Partition: kafka.PartitionAny,
},
Value: []byte("hello world!"),
}
}Now let’s send the message to the broker. To do this, we can send the message through the produce channel. It’s important to note that this is an asynchronous operation, so we may want to also wait for the report to come back. We can do this by taking a look at the events channel.
producer.go
func main() {
...
producer.ProduceChannel() <- record
defer producer.Close()
event := <-producer.Events()
msg := event.(*kafka.Message)
if msg.TopicPartition.Error != nil {
log.Printf("Error sending message to cluster: %s\n", msg.TopicPartition.Error)
} else {
log.Printf("Message sent to topic %s (partition %d) at offset %d\n",
*msg.TopicPartition.Topic, msg.TopicPartition.Partition, msg.TopicPartition.Offset)
}
}If you run go run producer.go you will see the following output:
output
2020/06/11 16:16:52 Message sent to topic test (partition 0) at offset 0Consuming messages
We’re now ready to consume some messages from the “test” topic! Setting up the consumer is very similar to how we set up the producer in the last section, but we also need to provide something called a group.id. I’ll touch on this property more in the next section.
consumer.go
func main() {
config := &kafka.ConfigMap{
"bootstrap.servers": "localhost:9092",
"group.id": "test-group",
}
consumer, err := kafka.NewConsumer(config)
if err != nil {
log.Fatalf("Error creating consumer: %s\n", err)
}
}Once we have created the consumer, we can subscribe to the “test” topic and poll for events that have been pushed to the topic. We will also set up a signal handler so that we can exit gracefully.
consumer.go
func main() {
...
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
consumer.Subscribe("test", nil)
for {
select {
case <-sigChan:
log.Println("Shutting down")
consumer.Close()
os.Exit(0)
default:
event := consumer.Poll(100)
if event == nil {
continue
}
switch e := event.(type) {
case *kafka.Message:
log.Printf("Received message with value: %s\n", e.Value)
case kafka.OffsetsCommitted:
log.Printf("Offsets committed: %s\n", e)
}
}
}
}If you run the consumer with go run consumer.go and then run the producer with go run producer.go, you will see something like this:
consumer output
2020/06/11 16:38:59 Received message with value: hello world!
2020/06/11 16:39:03 Offsets committed: OffsetsCommitted (<nil>, [test[0]@1])Horizontally scaling with consumer groups
At some point, you may eventually be producing thousands of messages per minute which could be a lot for just one consumer to manage. This is also completely ignoring the fact that you will want to have some sort of fault tolerance if a consumer suddenly goes down. Consumer groups can help you address both of these issues!
By having two different consumers within the same group, you are effectively splitting the workload between the two. The offset for the topic applies not to a specific consumer, but rather to its consumer group. This means that if one consumer within the group processes a message, the others will not consume that same message. Each consumer in a consumer group is assigned a set of topic partitions. To test this out you will first need to start up another Kafka broker and create a partitioned topic like so:
command line
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic test-partitionedStart by changing the topic in the producer and the consumer to be “test-partitioned”. Then start up two different instances of your consumer by running go run consumer.go in two separate terminals. Now, if you run the producer a few times with go run producer.go you will see how the consumers share the work.
consumer one output
2020/06/12 12:22:18 Received message with value: hello world!
2020/06/12 12:22:19 Offsets committed: OffsetsCommitted (<nil>, [test-partitioned[0]@unset test-partitioned[1]@15])
2020/06/12 12:22:25 Received message with value: hello world!
2020/06/12 12:22:29 Offsets committed: OffsetsCommitted (<nil>, [test-partitioned[1]@16])consumer two output
2020/06/12 12:22:29 Received message with value: hello world!
2020/06/12 12:22:32 Offsets committed: OffsetsCommitted (<nil>, [test-partitioned[0]@4])
2020/06/12 12:22:32 Received message with value: hello world!
2020/06/12 12:22:37 Offsets committed: OffsetsCommitted (<nil>, [test-partitioned[0]@5])Final thoughts
This is only a small sample of what you can do with Kafka, but I’m hoping to dig deeper into some of its other features and use cases in future posts. Thanks for taking the time to read this post, and I hope you’ll decide to stop by again soon! All of the code in this post is available on my GitHub.